4.1. Introduction to Programming with R¶
| Authors: | Martin Schultze |
|---|---|
| Citation: | Schultze, M. (2019). Introduction to Programming with R. In S.E.P. Boettcher, D. Draschkow, J. Sassenhagen & M. Schultze (Eds.). Scientific Methods for Open Behavioral, Social and Cognitive Sciences. https://doi.org/10.17605/OSF.IO/HCJG9 |
Perhaps the question I am confronted with most when teaching statistics courses to psychology undergrads is “Why should I need this, when I become a therapist”? That’s a difficult one to answer in a single sentence, but I will give it a try, nonetheless: “Because everything we know in psychology - and the social sciences in general - is connected to empirical data”. Well, it was a first try. As the previous sections of this volume have shown you, in scientific psychology we strive to test our claims using data. Testing our claims (ideally) leads to appropriate theories becoming successful and inappropriate theories being discarded. When you are working with patients or clients, would you not rather use techniques that have been proven to be successful in reducing negative symptoms?
Even more baffling to many of you, now reading these words, is the idea of learning a programming language like R in the first year of studying psychology. But the same reasons for learning statistics in general apply to learning R. To move from observations to conclusions requires multiple steps: encoding observations in data, organizing data, describing data, and testing hypotheses using data. The previous section showed you how to collect data in experimental settings using Python. In this and the following sections we will try to turn the data we gathered into conclusions about our hypotheses by using R - a multi-purpose tool that can be used for almost anything data-related.
4.1.1. Why R?¶
Many blogs are filled with heaps of reasons to use R over other software that was traditionally more prominent in the behavioral and social sciences. Here’s a rundown of the “best of”:
- It’s free
This is the obvious one: R costs you nothing to obtain or use. A lot of other software for data analysis requires you to either buy a specific version or rent a yearly license. R, on the other hand, you can simply download, install, and use. R is developed and maintained by `non-profit foundation<https://www.r-project.org/foundation/>`_, meaning it is free of commercial interests.
- It’s free
Yes, I’ve said this already, but this time it has a different meaning. This “free” pertains to the `definition of free software as proposed by GNU<https://www.gnu.org/philosophy/free-sw.en.html>`_, which can be boiled down to the phrase “the users have the freedom to run, copy, distribute, study, change and improve the software”. This means that R is an open source software and this applies not only to the R-core itself, but also to the packages, which you can obtain via the official repository. This allows everyone to see what is actually happening - e.g. which formulas are used to compute statistics - and catch mistakes in the software before you publish research that is flawed (see [Eklund2016] for what may happen, when software is not open for such checks).
- Researchers develop their tools in R and make them available as R packages
One important aspect of doing research is using the correct tools. Correct is often understood to simply mean “not wrong”, but in science there is a lot of nuance to “not wrong”. Some approaches may simply become outdated, because newer alternatives are available or because someone has developed an adapted version which is better suited for your specific case. Currently, many new methodological developments are implemented as R packages and made available for anyone to use. Commercial software is often slower to react, because there is not enough demand for the approach you might need, in order to implement it into a specific software. Thus, R is a more direct channel to current developments in analysis tools. To be able to use newly developed analysis tools comes with a few caveats, of course, because you lose the vetting process performed by commercial providers.
- You can develop your own approach and implement it in R
A lot of software is limited to what has been implemented by the developers. This is where R can really shine, because it allows you to implement whatever analysis you want, as long as you are able to formulate it in the R language. Because the most basic building blocks of R are simply mathematical operations and relations there is almost no limit to what you can implement. Be aware, that this does not mean that R is the best tool to implement whatever it is, you’re trying to implement; it simply means it is a tool that makes it possible at least.
- The community
There are hundreds of resources and websites containing tutorials, guides, comparisons of approaches, and assistance. Of course, R comes with help-files and examples and there is `an extensive list of FAQs<https://cran.r-project.org/doc/FAQ/R-FAQ.html>`_, but as is the case with most programming languages, the premier resource for specific questions is `stack overflow<https://stackoverflow.com/>`_. As I am writing this, there are currently 278380 questions tagged “R” on stack overflow, most of them with well-meaning, detailed responses.
But before we can get to experts’ opinions on stack overflow, there are some additional resources you can check, if the presentation in this volume leaves you with open questions. Maybe one of the websites that is visited most often in the early stages of learning R is the `Quick-R website by DataCamp<https://www.statmethods.net/>`_, where you will get quick answers to some of the early questions in an alternative way to our presentation here. Another way you may want to try to learn the first steps of R is through online courses like `Harvard's "Statistics and R"<https://online-learning.harvard.edu/course/statistics-and-r>`_ or `DataCamp's interactive "Introduction to R"<https://www.datacamp.com/courses/free-introduction-to-r>`_. There are also a lot of other courses out there, most of which are not free, however. Our hope is, of course, that you will be in no need for such resources once you are done with this and the following sections, but it cannot hurt to have alternatives.
- Everyone uses it
As, no doubt, your parents have told you on multiple occasions, this is perhaps the single worst argument on the planet to do something: “Would you jump off a bridge, if your friends did it?” Well, in this case, you might want to, because one of the core necessities for open and reproducible science is communicating your work. Not just results and conclusions, but also how you got there. As I stated above, R can be used for basically all steps between assessing data and producing manuscripts and if others use it, it may be necessary for you to be able to read what they wrote, to gain an understanding of how they structured, analyzed, and visualized their data. On the other hand, writing R code also allows other people to retrace the steps you took, because many people can read it. In 2017, Python and R were among the fastest growing programming languages - measured by the number of Stackoverflow views of questions tagged for either one of those languages ([Robinson2017a], [Robinson2017b]). On `Bob Muenchen's Website r4stats<http://r4stats.com/>`_ you will find a continuously updated Article with current numbers on the popularity of R ([Muenchen2019]), where it is among the most sought after skills in job descriptions and the second most common software cited in scientific articles.
4.1.2. Gathering your tools¶
Enough chit-chat about the benefits of R - chances are, that if you are still reading at this point, I do not need to convince you any further to use it. So, let us begin by gathering the necessary materials:
The R-Core¶
The best way to get R is to simply grab it directly from its provider. R itself and most utensils you can add on to it are gathered in what is called CRAN (Comprehensive R Archive Network). For some nice 90s nostalgia you can visit the `CRAN website<https://cran.r-project.org/>`_ directly, but we also provide short descriptions of how to Install R on Windows, Install R on Mac OS X, and Install R on Ubuntu below. And for those of you who do not want to run the risk of R withdrawal symptoms: `here's a link to a short description of how to install it on an Android device<https://selbydavid.com/2017/12/29/r-android/>`_.
Install R on Windows¶
Installing R on Windows machines is pretty straightforward. The CRAN Website provides you with an executable for the installation of the latest stable R Version, which you can `download here<https://cran.r-project.org/bin/windows/base/release.htm>`_. The only thing you have to keep in mind is that R does not perform automatic updates. That’s where it becomes a bit tricky: it is advisable to check for a new R version every now and again - a good estimate going by `the R version history<https://cran.r-project.org/bin/windows/base/old/>`_ is every three months. To update R it is recommended to install a new R version alongside your current version, just in case the new R version broke something that worked before. For some more details on this procedure (and many others), feel free to check the `R for Windows FAQ<https://cran.r-project.org/bin/windows/base/rw-FAQ.html>`_
Install R on Mac OS X¶
Current versions of R are only available for OS X 10.11 (El Capitan) and above. Since this OS is now five years old, the newer versions should cover most users, but if you are among those running an older version of OS X, you will need to install either R Version 3.3.3 (OS X 10.9 and 10.10) or R Version 3.2.1 (OS X 10.6 to 10.8). All three versions can be `found here<https://cran.r-project.org/bin/macosx/>`_.
Prior to installing R on OS X 10.8 or above, you will need to install XQuartz. Simply `download the dmg-file from the XQuartz-Website<https://www.xquartz.org/>`_ and follow the instructions provided in the installer. Afterwards, please restart your computer, before installing R.
To install R after having installed XQuartz, again simply download the `installer provided by CRAN<https://cran.r-project.org/bin/macosx/>`_ and run it. Should you be asked to install XCode during this process, please do so. As was the case with R for Windows, R does not perform automatic updates, so you should check for a new version every three months or so.
Install R on Ubuntu¶
R can be installed from the repositories for many Linux distributions. We will cover the case for Ubuntu here, but you can find an online tutorial for installing R on RedHat on `this blog<https://blog.sellorm.com/2017/11/11/basic-installation-of-r-on-redhat-linux-7/>`_, for example.
To install R on a Ubuntu machine, you will need sudo-permissions. Because R is part of the Ubuntu repositories, you can simply install it via:
sudo apt install r-base
However, this will provide you with an outdated version of R in most cases. To obtain the new version of R (and have it update automatically), there are some additional hoops. First, you need to add the necessary GPG key:
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys E298A3A825C0D65DFD57CBB651716619E084DAB9
Then, you need to add the R repository to your sources list. Depending on the Ubuntu release you are running, this may look like this:
sudo add-apt-repository 'deb https://cloud.r-project.org/bin/linux/ubuntu bionic-cran35/'
if you are running Bionic Beaver, or like this:
sudo add-apt-repository 'deb https://cloud.r-project.org/bin/linux/ubuntu cosmic-cran35/'
if you are running Cosmic Cuttlefish. If you are running a different release, simply replace the bionic or cosmic by the name of your version.
Because this changes the /etc/apt/sources.list file, you will need to:
sudo apt update
which may take a few seconds. Afterwards, you can install R using:
sudo apt install r-base
which should provide you with the current version. In contrast to installing R on Windows or OS X, this will provide you with automatic updates for R.
Running R for the first time¶
To run R, either open a terminal (for the OS X and Linux users out there) or run the RGUI program you just installed on your Windows machine. You should be greeted by a wall of text, looking something like this:
## R version 3.5.3 (2019-03-11) -- "Great Truth"
## Copyright (C) 2019 The R Foundation for Statistical Computing
## Platform: x86_64-pc-linux-gnu (64-bit)
## R is free software and comes with ABSOLUTELY NO WARRANTY.
## You are welcome to redistribute it under certain conditions.
## Type 'license()' or 'licence()' for distribution details.
## Natural language support but running in an English locale
## R is a collaborative project with many contributors.
## Type 'contributors()' for more information and
## 'citation()' on how to cite R or R packages in publications.
## Type 'demo()' for some demos, 'help()' for on-line help, or
## 'help.start()' for an HTML browser interface to help.
## Type 'q()' to quit R.
There’s a few things to pick apart here, so let’s start at the top:
R Versionobviously states the current version of R you are using, with its release date and nickname. I have tried and tried to figure it out, but, as shared by `MattBagg on Stackoverflow<https://stackoverflow.com/questions/13478375/is-there-any-authoritative-documentation-on-r-release-nicknames>`_, there is apparently no system in the nicknames.free software: we talked about this above - R is free and free, so you may do with it whatever pleases you. When redistributing it, however, you should keep the license in mind.ABSOLUTELY NO WARRANTY: this is the big reason some companies are still hesitant to use R in high-stakes situations. If your results are wrong because there is an error somewhere in the R-package you are using to perform your analysis, there is no one you can (legally) blame, but yourself for not checking the code thoroughly enough. Now keep in mind, that this is very rare, because most researchers publishing R packages do not just throw any half-baked ideas on CRAN, because their reputations are also tied to their work. The idea is simply, if you want to be sure everything is correct, check for yourself.how to cite R or R packages in publications: this is the last point I want to highlight. Many people pour years of their lives into making the procedures work that you can then use for free. Please reward their work by citing them correctly, if your are using it. As a matter of fact, let us make this the first R command we perform:
citation()
##
## To cite R in publications use:
##
## R Core Team (2019). R: A language and environment for
## statistical computing. R Foundation for Statistical Computing,
## Vienna, Austria. URL https://www.R-project.org/.
##
## A BibTeX entry for LaTeX users is
##
## @Manual{,
## title = {R: A Language and Environment for Statistical Computing},
## author = {{R Core Team}},
## organization = {R Foundation for Statistical Computing},
## address = {Vienna, Austria},
## year = {2019},
## url = {https://www.R-project.org/},
## }
##
## We have invested a lot of time and effort in creating R, please
## cite it when using it for data analysis. See also
## 'citation("pkgname")' for citing R packages.
Using the citation() function provides you with an overview and a BibTeX source for citing R. If your analysis was performed in R, please use this function to cite it correctly.
RStudio¶
The official way to interface with R is either via command line (if you are using OS X or Linux) or using the R GUI (if you are using Windows). Both approaches are very limited in their depiction of information and some might even want to call them ugly. This is why there are multiple frontends you can use for R. For those of you, who are already proficient in Emacs, there is `ESS (Emacs Speaks Statistics)<http://ess.r-project.org/>`_, which allows you to interact not only with R, but with a lot of other statistical programming languages as well. For those who enjoy a more customizable interface, I would highly recommend `Atom<https://atom.io/>`_, which allows you to interface with Python and R in the same environment and comes with integrated git-functionality. `Here is a quick description of how to get both working in Atom<https://jstaf.github.io/2018/03/25/atom-ide.html>`_. However, the most widespread IDE for R is, by far, RStudio.
RStudio is a company based in Boston, MA, developing a variety of different products centered around R. Their initial product was the IDE RStudio, which provides a much nicer GUI for R, than the original. The benefit of RStudio over the other possibilities I talked about above is that it is specifically designed for R and all of its little quirks. Thus, it is not a multi-purpose programming tool, but is focused on giving you the easiest and most intuitive way to interact with R, making it a good tool for learning and using R. Beyond that it works identically across all platforms (Windows, OS X, and Linux), making it a good tool for teaching. It also integrates some extensions on R (like R-Markdown for reporting), which we will get into later in this volume.
To install RStudio, simply `visit its download page<https://www.rstudio.com/products/rstudio/download/#download>`_ and choose the appropriate version for your system. Be aware, that RStudio is simply a frontend and requires you to have installed R as described in the previous section. In contrast to R, RStudio comes with an integrated possibility of updating - this does not update R, however! So you will still need to check for a new version every three months or so, if you are working on a Windows or OS X machine.
Everything we will do in R in the following sections can be done without RStudio, using either just the command-line version of R or any other IDE. Using RStudio is simply a recommendation to ease your way into using R.
When you start up RStudio, the first thing you should do is to open a new R script. You can do this with Ctrl+Shift+n (or Cmd+Shift+n, if you are using OS X) or via . After doing so, your RStudio window should look something like this:
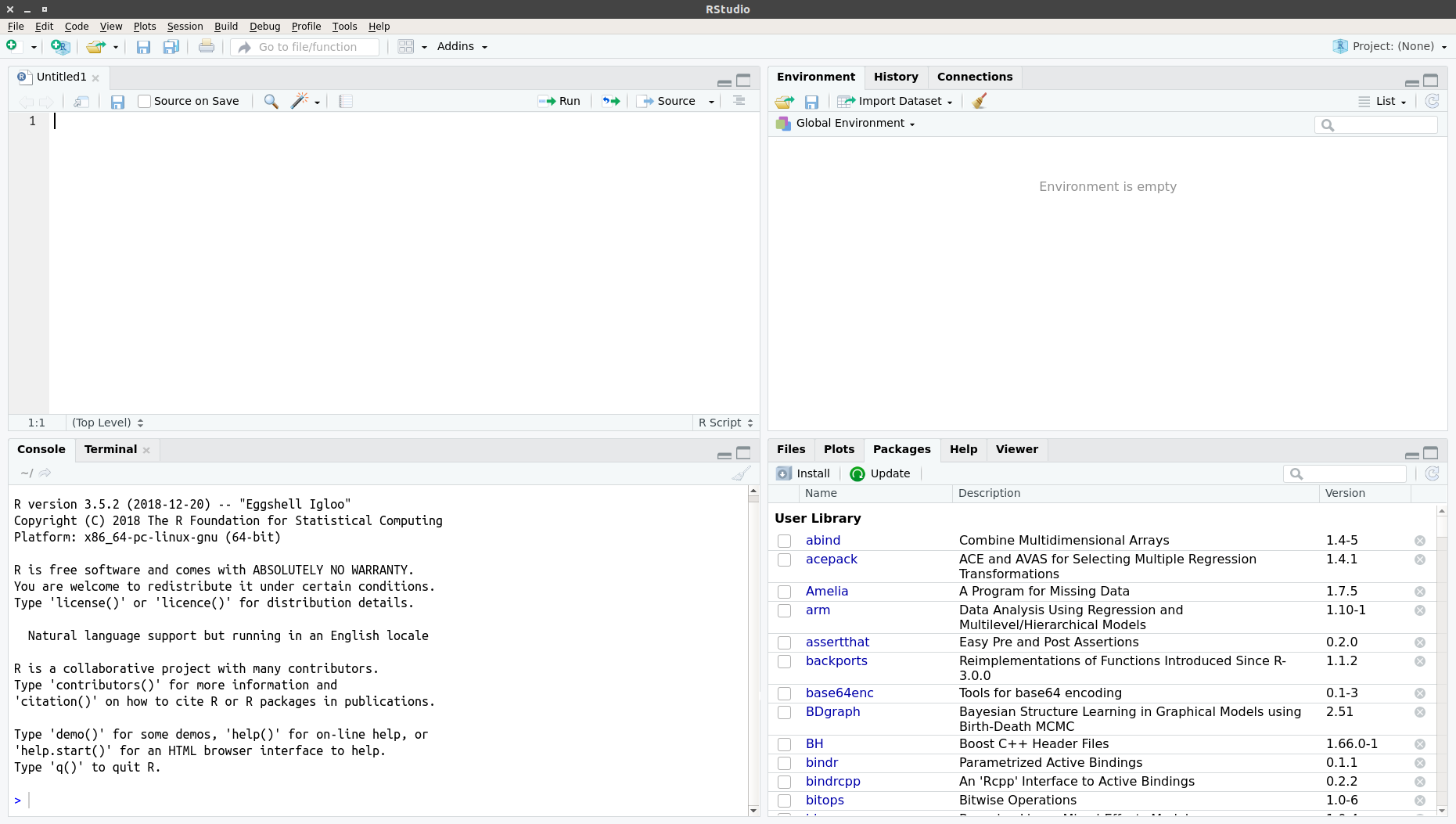
RStudio just after opening a new R script.
There are four basic panes in this window. In the top left you have the R script you just opened. This is the spot where you can generate your code. Writing the code does not do anything until it is executed. You can run the R code either by clicking the Run-button (in the top right of this pane) or by using Ctrl+Enter. For example, typing in 3 + 4 and executing it will send the command (3 + 4) to the console (the pane on the bottom left). Here you should then have:
3+4
as a mirror of what you executed and
## [1] 7
as the result. The layout will be a bit different from what you see on this website: your commands should be preceded by a prompt > and, by default, be in blue, while the result should be in black. Throughout the sections of this volume dealing with R, results will always be preceded by the double hash: ##.
These two panes are what you would find in almost any frontend you could use to interact with R. Where RStudio starts to shine is the remaining two. In the top-right you see a pane labeled “Environment”. The other two tabs of this pane are rarely of relevance, so just concentrate on the Environment for now. This pane shows you everything that is currently active in R. We will get into this in a second, but believe me: this makes the first steps in R much easier, because you always have a quick overview of all data you are currently working with. To bottom-right pane has five tabs - all of which are relevant. “Files” gives you the possibility to navigate and open files in R. “Plots” is pretty much self explanatory and we will be generating some nice plots soon. The next tab (the one opened by default) is called “Packages” and gives you an overview of all the extensions for R that are currently installed. You can install new ones and load the ones you have installed from here, but we will be looking at more reproducible way of handling packages in a bit. Perhaps the single most important tab here is the one labeled “Help”. Whenever you want to know how a function works, what it does, or how to interpret its output, the help will be opened here.
We have only just started to scrape the surface of what RStudio is and what it can do. If you want some more information on it, the documentation provided by RStudio is great. There are tons of `webinars for specific topics<https://resources.rstudio.com/webinars>`_, there is a `quick overview of how to learn to use RStudio online<https://www.rstudio.com/online-learning/>`_, and best of all, there are `a lot cheat-sheets for RStudio and the packages developed by the RStudio team<https://www.rstudio.com/resources/cheatsheets/>`_. From here on, we will not be focusing on RStudio, but more on the core functionality of R. Feel free to do everything we do in the upcoming sections in RStudio, however.
4.1.3. Some first, wobbly steps¶
Let’s start out with some basics of R code. Because the goal of using R is to write code that leads to reproducible data analysis and results, there are some things you need to know about the general use of R, which we will combine with some hands-on code writing. So, if you have not opened R yet, it is probably time to do so now.
Commenting and basic functionality¶
Use comments for everything. I can not stress this enough. Comments are your way of communicating to others and - most often the more important case - to your future self, what you are doing and why. This goes beyond simple small comments and extends to structuring your code. RStudio does a good job of encouraging this, by allowing you to collapse entire sections of your code, if you are currently not interested in looking at it. For the most basic structure, I would recommend using the simple comment character # for small comments and notes. For section titles I recommend beginning the title with #### and ending it with ----. RStudio will automatically recognize this as the section header, but even if you are using something else, this will help you keep your code organized and readable. Let’s see how this works with some simple calculations in R:
#### Simple calculations ----
3 + 4 # Addition
3 - 4 # Subtraction
3 * 4 # Multiplication
3 / 4 # Division
3 ^ 4 # Powers
Here the section is titled “Simple calculations” and each type of calculation is described in a short comment. Now, this may be overkill, but you get the point.
As you can see, I have always left a space between the numbers and the operations. R does not care about empty space. You can even use indentation to help you organize your code without changing the functionality of your code. Beyond this, you do not need to end lines with any specific character - a simple line break ends a line. It is generally recommended to write R as you would write normal sentences, using appropriate spaces to enhance the readability of your code. If you want a detailed style guide for R code, there are `general recommendations published by Google<https://google.github.io/styleguide/Rguide.xml>`_.
Now, as we have seen before, executing the basic calculations in your code will result in you receiving a copy of the code you executed, as well as a numeric result in your console. Let’s take the division example:
3 / 4 # Division
## [1] 0.75
Of course, numeric results are just one kind of result you can obtain from R. As you have seen above, we are often also interested in logical returns. In R, these work something like this:
#### Logical relations ----
3 == 4 # Equal?
3 != 4 # Unequal?
3 > 4 # Greater than?
3 < 4 # Smaller than?
3 >= 4 # Greater or equal?
3 <= 4 # Smaller or equal?
The first one, as you should expect, returns
3 == 4 # Equal?
## [1] FALSE
and the second one returns
3 != 4 # Unequal?
## [1] TRUE
Internally, TRUE is coded as a 1, while FALSE is coded as a 0. Besides making sense, this also results in a lot of nice properties, we will be making use of soon. One quick tip: as with most programming languages the ! denotes negation in R, so you could also construct a more complicated version of != by hand:
!(3 == 4)
## [1] TRUE
which can be read as “not (3 equals 4)”. Because the parentheses are evaluated first, they return a FALSE and this result is negated by !, leading to the final TRUE. Why would you ever need this? Well, we will see.
Functions and arguments¶
What we have looked at so far are simple calculations and equality/inequality checks. These are somewhat special, because the deviate from the “normal way” of doing things in R. Normally, you use functions in R. Using the basic addition shown above, you would write:
3 + 4 + 1 + 2
## [1] 10
but the way more akin to how R works in all other instances is by using the sum function.
sum(3, 4, 1, 2)
## [1] 10
Now, from this simple example you can already derive the basics of how functions work in R. The general structure is always
function(argument1, argument2, argument3, ...)
As you can see, the name of a function is written first and all the arguments the function requires are passed to it in parentheses, separated by commas. The sum function is special in a way, because it can basically take an infinite number of arguments. Let’s look at a more prototypical function:
log(100)
## [1] 4.60517
As you can see, this returns the natural logarithm of 100. However, what if I want a logarithm with a different base? Because we are using 100 as the example, the simplest logarithm would be of base 10:
log(100, 10)
## [1] 2
Let us untangle how this works. Remember your school math: \(\log_{\text{base}} \text{argument} = \text{answer}\). So, the log function takes the \(\text{argument}\) as its first argument and the \(\text{base}\) as its second argument. Now, because most people simply cannot remember the correct order of all arguments for the unbelievable number of functions you can use in R, there is a second way of using functions:
log(x = 100, base = 10)
## [1] 2
In this approach, you need to name the arguments, but are now free to provide them in any order you wish:
log(base = 10, x = 100)
## [1] 2
How can you ever know the names and order of the arguments to a function? There are a few different possibilities, the quickest one is probably:
args(log)
## function (x, base = exp(1))
## NULL
So what does this mean? The function log has two possible arguments: x and base. However, what base = exp(1) tells you, is that there is a default in place for the base-argument. So, if you do not provide a value for this argument, the default is used. In this case \(e\) is defined for the exponential function exp, but not separately. So if you use the log-function, exp(1) is evaluated and passed to log as an argument. This already shows you that functions can be nested in R: the exp-function needs to be evaluated to provide an argument for log, so it must be evaluated first. This leads to the same simple principle you find in equations, which can make complicated R code frustrating to read: nested functions are evaluated from the inside out. There are several ways to avoid this, which we will get to in bit.
Getting and using help¶
While we used args to get a quick overview of the arguments for the logarithm in R in the previous section, R actually comes with a very good integrated help system. For any function you know the name of, you can simply use the help function. In most cases, this is opened in a new window or pane, which means you can have the help opened at all times. I would encourage you not to be shy about your usage of help. It is a much better, efficient way of learning R than typing and retyping arguments over and over. If you are using RStudio, Atom, or something similar, there is also often some form of auto-completion to help you with functions and their arguments. If it is too much effort for you to type help(function), you can also use ?function to achieve the same result.
So, let’s look at the help for the logarithm:
help(log)
opens up the help file for the log function. You can scroll through this help, but here is a short rundown of the basic layout of any R help file:
Description: Usually a very short overview of what the function does.
Usage: The basic structure of the function. This contains all of the arguments you can use. In some cases, like the one you are currently looking at, this may contain multiple functions that are documented together, because they work in the same way. As we discussed above, if an argument is followed by = something, it has a fixed default. If you do not provide a value for that argument, the default is used. Conversely, this also means that any argument not followed by the equals-sign does not have a default an must be provided.
Arguments: This shows you a list of all the arguments the function accepts with a brief description of what they do and which format they must adhere to.
Details: Additional information you may want. For functions that perform complex analysis, this may contain a detailed description of the procedure with appropriate citations.
Values: A list of all the output a function produces. In R results of functions are often much bigger than what is printed, when you use them. The values listed here are all the values that are returned, even though you may not see or interact with them on a regular basis.
See Also: If you did not find what you were looking for, maybe these similar functions can help you.
Examples: Maybe the most important section. All documentation in R must ship with minimal working examples. Often the list of arguments can be overwhelming, so you may want to scroll to the bottom to look at the examples in order to see the functions in action. What you can do is copy examples and paste them into your R script to execute them. Basically, this is the same as asking the judges to hear the word in sentence when you were contestant in a spelling bee.
Apropos¶
apropos is function you can use instead of help. Using help requires you to know the exact, specific name of the function you need help with. Most of the time that is not the situation you need help in. Often the actual name of a function eludes you, which is where apropos (or its short version ??) comes into play.
apropos(logarithm)
should open a list of some possible functions you could have meant. From here, you can navigate the help files of these functions.
Messages, warnings, and errors¶
There is no way around it: mistakes happen. When using R, especially in the learning phases, you will produce code that is incorrect, produces errors, or does not do what you expected it to. It is important to know, that this is nothing to be afraid of. One of the advantages of R is that it is made for people who are not professional programmers, so it is rather forgiving in how mistakes can be handled. Because you can execute R code a line at a time, you can avoid the anxious time spent waiting for your code to compile before punishing you with error messages. Instead, you get an immediate feedback on what you did wrong - always think of this, when you are struggling through countless R errors.
On a fundamental level, R has three ways (in addition to just producing correct output) to communicate with you: messages, warnings, and errors.
Messages are simply a sign of a chatty programmer. Often times they provide information about the options with which you invoked a function or tell you about a package being in a beta-State. The startup we looked at in the section Running R for the first time, was such a message: it gives you additional information. You can produce messages yourself:
message('I am peckish.')
## I am peckish.
This makes sense if you are running long scripts or writing your own functions and want to produce some output to give you a progress update, for example.
The second tier are warnings:
warning('I am hungry.')
## Warning: I am hungry.
Warnings indicate that something probably did not go as planned. This means that the function you called still produced output, but you should check to see, whether it is really what you wanted. You can produce a warning for the logarithm-example by
log(-1)
## Warning in log(-1): NaNs produced
## [1] NaN
This still produces output (NaN, meaning ‘Not a Number’), but tells you that something went awry in a warning message. If you produce a lot of warnings (more than 10, by default) R will simply say something like There were 11 warnings (use warnings() to see them). Then, executing warnings() will give you a detailed output about the warnings you produced. If you really produce a lot of warnings (more than 50, by default) R will stop counting them and only return the first 50 when you invoke warnings().
The third tier are errors. Errors mean, that the function you called was aborted and that no output was produced. A typical error is providing the wrong arguments to functions:
log(argument = 10)
## Error in eval(expr, envir, enclos): argument "x" is missing, with no default
Just like messages and warnings, you can also produce them yourself
stop('I am starving.')
## Error in eval(expr, envir, enclos): I am starving.
Note that errors are produced using the stop function, not with a function called error. This underlines that the code is stopped at that point. If you are writing a function this means that the execution of the function is aborted at that point and that the error-message you provided is returned. In long scripts this does not mean, that the next line will not be executed, however! Because the next line is a new command, R will simply continue on without having produced the previous results, which can often result in very long chains of errors.
The text produced by warnings and errors is written to be useful in all cases, in which they can occur, so it often does not seem all that helpful. However, once you develop a better understanding of the inner workings of R, you will start noticing that they actually tell you exactly what the problem is.
Objects and the Environment¶
Now we are really getting into the bread and butter of R. What we saw above - typing in a function and getting a result printed out - is less frequently of interest in R than storing results of a function and using them again in some other fashion. It is also where R gains a leg-up on many of its competitors in the market of data analysis software. Storing results from one type of analysis and then using these as the data for a different type of analysis gives you the flexibility of doing whatever you want with R. Its implementation is also extremely intuitive, so let us take a look:
my_num <- sum(3, 4, 1, 2)
As you can see, you did not get a result. The result of the sum is simply stored in the object called my_num. The arrow <- assigns the result of the right side to whatever object is on the left side. This also works in reverse:
sum(3, 4, 1, 2) -> my_num
but the first version is much more common, because it allows you to see the objects you have created faster. One important thing that just happened, that I want to draw your attention to, is that there was no warning whatsoever. In R objects are simply overwritten if you assign new content to them, so it is best to be very aware of the names for objects that you have already used. This makes it doubly important to use distinctive names for your objects (the other reason being that you want to know what is happening). The `Google Styleguide for R<https://google.github.io/styleguide/Rguide.xml>`_ that I mentioned above also contains some guidelines on how you should name your objects. These are only guidelines, however, and objects can have any name that does not start in a number.
Now that results are in an object, how do we get access to them? The easiest way is to simply write the name of the object:
my_num
## [1] 10
which is shorthand for writing print(my_num) or (my_num). But the goal of assigning values and results to objects is to be able to pass them on to other functions. So, in this simple example:
sqrt(my_num)
## [1] 3.162278
passes our object to a function. This is essentially the same as:
sqrt(sum(3, 4, 1, 2))
## [1] 3.162278
which evaluates the sum and then passes its results to sqrt. As you have probably guessed, there is no end to the possibilities of nesting functions or creating objects. So
my_root <- sqrt(my_num)
uses the object my_num as an argument in the square-root function and then stores the result in a new object called my_root.
Again, we decided how to name this object. Instead of naming it my_num, we could have named it cheesecake or captain_marvel. Of course these names would not be very descriptive and would probably confuse us in the future as well as others trying to use the code.
If you are using RStudio you have probably realized that both objects have appeared in the Environment tab of top-right pane. RStudio gives you continuous information on what you are currently working with. Any object in the global environment (the one you are currently working in) can be accessed, used, and overwritten. The traditional R way of looking at your environment is
ls()
## [1] "my_num" "my_root"
which lists all objects and functions that you have created. If your workspace has gotten out of hand, you can also list only some objects with
ls(pattern = 'num')
## [1] "my_num"
This shows you all objects which contain num in their name. Removing objects from your workspace is also quite simple:
rm(my_num)
ls()
## [1] "my_root"
Again, notice that you do not get a warning - the object simply disappears - so you might want to be rather careful with using rm. If you want everything in your workspace to disappear and start over with a blank slate, you can combine rm and ls:
rm(list = ls())
where you simply provide the entire environment (as produced by ls) as an argument to rm.
4.1.4. Handling data¶
As you saw in the previous section, objects are where results and numbers are stored. Data you assess is no different, it is only bigger. As discussed in an earlier chapter, variables are the basis of assessing behavior and multiple variables are combined into datasets.
R is extremely rarely used to manually input any data. Most of the time it is either imported from a program you used to assess your experimental data (e.g. from Psychopy), downloaded from a provider you used for assessing data online (from Limesurvey, Unipark, or something similar) or transferred from a different source of data storage (e.g. from an Excel-Sheet). Nevertheless, knowing how data can be created in R can be an incredible help to understanding how data is structured, when it comes from somewhere else.
One more important thing before we continue. In case you were testing all of the previous commands directly in the console, I would like to remind you that we have a script open. This should be used for writing down and commenting the code from this exercise. Do not forget to regularly save it, as you would any other work in progress. You can copy-paste the commands from the following sections into your script, give them a descriptive comment and execute them right from the editor. Just select the row you would like to execute and hit the Run button. You can also use the Ctrl + Enter shortcut (Cmd + Enter on Macs).
Vectors¶
So let us build a minimal example: say you observed reaction times of five participants in a `Stroop test<http://www.yorku.ca/pclassic/Stroop/>`_ ([Stroop1935]), one of the classics of experimental psychology. The basic idea is best conveyed in a picture:

The Stroop effect is the difference between the time it takes you to correctly name the color a word is printed in, when the word and text color match versus when they do not (see [MacLeod1991] for an overview over the first 50 years of its existence). If you want to see how it works, you can check your performance in an online version on `Open Cognition Lab<http://opencoglab.org/stroop/>`_, for example.
Now, let’s say you measured six reaction times manually, by administering a minimal version of the Stroop to a friend. The times could be (in milliseconds) 597, 1146, 497, 938, 1080, and 1304. To input data as one vector in R, you can use
react <- c(597, 1146, 497, 938, 1080, 1304)
Calling the help function on c (as discussed in Getting and using help) reveals that it is a basic function to combine all arguments (in this case six reaction times) into a single object. This object is a vector: a one-dimensional array of information, which is of the same type. You can find out what type of vector you just stored your information in in multiple ways. We can use
class(react)
## [1] "numeric"
to start, because that provides us with the most basic information about the object react: it is a numeric vector. Using
str(react)
## num [1:6] 597 1146 497 938 1080 ...
we obtain a bit more detailed information about the structure of the object: it is numeric (num), it contains the elements one through six ([1:6]), and we see a preview of this object, namely its first five elements.
There are three general types of vectors in R:
| Type | Shorthand | Content |
|---|---|---|
logical |
logi |
TRUE or FALSE |
numeric |
num |
Any type of number |
character |
chr |
Any combination of letters and numbers |
Continuing with the Stroop example, the color of the text that was presented is relevant information. We could encode this in a character vector:
color <- c('green', 'purple', 'blue', 'purple', 'red', 'green')
We can check whether this is a character vector with
is.character(color)
## [1] TRUE
In general, the is. prefix can be combined with all types of data storage in R, to check whether it is of that type. The same goes for as. which can be used for a simple attempt to convert data from one type to another. For the vector-types we have seen, you could use
as.numeric(color)
## Warning: NAs introduced by coercion
## [1] NA NA NA NA NA NA
As you can see, this produces a warning (see Messages, warnings, and errors) and the resulting vector contains only NA. This is R’s way of encoding the absence of information and is short for not available. This occurs, because R has no idea how to transform the word 'green' into a number. Using the basics of measurement theory that were discussed in an earlier chapter, we know that what R is missing is some form of adequate relation. We will discuss how this is done in Factors, but for now, let us continue with vectors.
Next to the color, the actual text we are presented with in the Stroop test is also quite important. So, we can generate another character vector:
text <- c('green', 'purple', 'blue', 'green', 'blue', 'red')
Now, the core effect found by [Stroop1935] is that the reaction is slower, when the color and the text are incongruent. We can use the logical relations shown in Commenting and basic functionality to generate a logical vector:
cong <- color == text
In Commenting and basic functionality we saw how comparisons work, when we compare two elements. An incredible positive about R is that most things (e.g. functions and mathematical operations) also work when applied to entire vectors or matrices of data. What happened in this instance, is that the elements in color and the elements in text were compared one-by-one: is the first element in color the same as the first element in text? Is the second element in color the same as the second element in text? And so on… This results in a logical vector of the same length as the two original vectors, because they were compared element-wise:
cong
## [1] TRUE TRUE TRUE FALSE FALSE FALSE
As you can see, this is a logical vector:
is.logical(cong)
## [1] TRUE
Factors¶
R’s way of storing variables with a nominal or ordinal scale is a type of special vector called a factor. These factors have the special property of being numeric while also storing information about what each numeric value means. Take the color variable from our example: we can convert the character vector containing the colors of the presented to a factor by using
color_fac <- as.factor(color)
and to obtain some overview of what this now looks like:
str(color_fac)
## Factor w/ 4 levels "blue","green",..: 2 3 1 3 4 2
As you can see, this factor contains numeric values (2 3 1 3 4 2), but also encodes what each of these numbers mean, by assigning levels. To see all levels of a factor, you can use
levels(color_fac)
## [1] "blue" "green" "purple" "red"
As you can probably guess, the numeric values are assigned by the way these levels are ordered. Because the original we converted to a factor was a character vector, these levels are ordered alphabetically. Specifically, all unique values of the vector:
unique(color)
## [1] "green" "purple" "blue" "red"
are ordered and then used as the levels of the factor. Printing the contents of the factor returns the levels, which are associated with each value, not the number that is stored:
color_fac
## [1] green purple blue purple red green
## Levels: blue green purple red
which is much more useful, because we will rarely have code-book lying next to our screen where we can look up what each number means. Additionally printing a factor returns the possible values, meaning all levels of the factor. Be aware that this makes it possible to have levels of factors, which are not realized in the data.
The dual storage of information makes it, so that factors can easily be converted to numeric or character:
as.numeric(color_fac)
## [1] 2 3 1 3 4 2
as.character(color_fac)
## [1] "green" "purple" "blue" "purple" "red" "green"
whichever is more relevant at the moment. However, even though there are numbers associated with each level, the order of the values is arbitrary, meaning normal factors encode nominal scales. You can even change which level comes first, i.e. which level is the reference level, by using:
color_fac <- relevel(color_fac, 'green')
This command overwrites the original object color_fac with a new version, where 'green' is the first level. All other levels are simply moved back:
levels(color_fac)
## [1] "green" "blue" "purple" "red"
If your original is a character vector, the strings are simply used as the levels. If your original vector is numeric, this does not really help you. Take the numeric version of our colors:
color_num <- c(2, 3, 1, 3, 4, 2)
and convert it to a factor:
color_fac2 <- as.factor(color_num)
levels(color_fac2)
## [1] "1" "2" "3" "4"
the resulting levels are not really helpful. In this case, you can provide new levels to the object.
levels(color_fac2) <- c('blue', 'green', 'purple', 'red')
color_fac2
## [1] green purple blue purple red green
## Levels: blue green purple red
Let’s take a quick look at how this works: there are four levels (1, 2, 3, 4) from the conversion of the numeric vector. These four levels can be provided with new labels (blue, green, purple, red). Thus, it is important that there are actually four levels, which we assign to the levels attribute. We don’t need to assign the values for each observation of the variable, only the unique levels.
Now, as I’ve noted, normal factors encode nominal scales. You can also encode ordinal variables with the ordered type. Say we ordered the colors by their wavelengths: purple (with the shortest wavelength), blue, green, red.
color_ord <- as.ordered(color)
color_ord
## [1] green purple blue purple red green
## Levels: blue < green < purple < red
Well that’s not what we wanted. I will leave it up to you to find out how the correct order of colors can be achieved in this case! At this point, all you need, is to be aware that unordered (i.e. nominal) and ordered (i.e. ordinal) variables can both be used in R. As a matter of fact, this is one of the many cases in R, where one is simply a special version of the other:
is.factor(color_ord)
## [1] TRUE
is.ordered(color_fac)
## [1] FALSE
meaning that ordered is a special case of factor.
Combining data¶
As a result of the section on Vectors, we have four different objects in our environment, which all relate to the same thing. Naturally, the best idea would be to combine them somehow. As with vectors, there are multiple types of storing data sets in R, but their relationships are a bit more complicated. Let’s get a general overview:
| Type | Content |
|---|---|
matrix |
Vectors of the same length and type (two dimensional) |
array |
Vectors of the same length and type (n-dimensional) |
data.frame |
Vectors of the same length |
list |
Any objects |
As you can see, the types are more specialized the further to they are to the top of the table. More specialized types restrict your possibilities of combining arbitrary information, but make storing and handling data more efficient in terms of computational power. Especially when handling abstrusely large data (such as raw fMRI or genetical data), I would highly recommend using matrices. Matrices are especially useful, because you can simply apply matrix-algebra to them, making computation and data analysis much easier.
As you can probably tell from the table, a matrix is a special case of an array - the two dimensional one. Less obvious is the fact that :code:`data.frame`s are special cases of :code:`list`s, i.e. the one where all content is of exactly the same length.
Let’s begin by constructing a matrix. For this, we need to ensure that the objects we intend to combine are of the same type and of the same length:
class(color)
## [1] "character"
class(text)
## [1] "character"
length(color)
## [1] 6
length(text)
## [1] 6
or, more simply:
class(color) == class(text)
## [1] TRUE
length(color) == length(text)
## [1] TRUE
If we want to combine these two to a matrix, there are multiple ways, but the two main approaches are, by either using the matrix function or by using cbind. We will use the second approach here, but I encourage you to take a look at help(matrix) and try this approach to reconstruct what is happening here.
The function cbind refers to binding vectors together as multiple columns. Traditionally, data frames are organized in such a fashion, that columns represent different variables, while rows represent different observations (e.g. people). If you wanted to combine data from different people that were observed on the same number of variables (e.g. the six reaction times of two different people) you would use rbind, for binding multiple rows. In our case, we can combine text and color to a matrix:
mat <- cbind(color, text)
The resulting object is a matrix:
class(mat)
## [1] "matrix"
but - because matrices are special cases of arrays - it is also an array!
is.array(mat)
## [1] TRUE
What matrices are not, is special cases of :code:`data.frame`s or :code:`list`s:
is.data.frame(mat)
## [1] FALSE
is.list(mat)
## [1] FALSE
Combining color and text worked, because both are of the same type (character). However, the data we have is also numeric (the reaction times) and logical (the indicator of congruence). If you combine all of them using the cbind command, the following will happen:
mat <- cbind(color, text, cong, react)
mat
## color text cong react
## [1,] "green" "green" "TRUE" "597"
## [2,] "purple" "purple" "TRUE" "1146"
## [3,] "blue" "blue" "TRUE" "497"
## [4,] "purple" "green" "FALSE" "938"
## [5,] "red" "blue" "FALSE" "1080"
## [6,] "green" "red" "FALSE" "1304"
All vectors were combined, but they were all converted to the most general type of vector of the three: character. This is bad, because you loose the numeric information in the variable react and can not use it for calculations and statistical analysis.
This is why, in most cases you will encounter with behavioral data, :code:`data.frame`s are the type of storage needed. You can combine the four vectors like this:
dat <- data.frame(color, text, cong, react)
This results in a data.frame with six rows and four columns. You can check this with the specific functions nrow and ncol, or get a general overview with:
str(dat)
## 'data.frame': 6 obs. of 4 variables:
## $ color: Factor w/ 4 levels "blue","green",..: 2 3 1 3 4 2
## $ text : Factor w/ 4 levels "blue","green",..: 2 3 1 2 1 4
## $ cong : logi TRUE TRUE TRUE FALSE FALSE FALSE
## $ react: num 597 1146 497 938 1080 ...
dat
## color text cong react
## 1 green green TRUE 597
## 2 purple purple TRUE 1146
## 3 blue blue TRUE 497
## 4 purple green FALSE 938
## 5 red blue FALSE 1080
## 6 green red FALSE 1304
As you can see, R automatically converts character vectors to factors! This is because that is what is most often desired. As with (almost) all behavior of R, you can adjust this. As we saw in Functions and arguments, this is only a matter of identifying the correct argument and changing its value. You can check help(data.frame) and will see that the argument we are looking for is aptly named stringsAsFactors. So:
dat2 <- data.frame(color, text, cong, react, stringsAsFactors = FALSE)
will provide us with a data.frame in which the character vectors remain as such. We can check:
str(dat2)
## 'data.frame': 6 obs. of 4 variables:
## $ color: chr "green" "purple" "blue" "purple" ...
## $ text : chr "green" "purple" "blue" "green" ...
## $ cong : logi TRUE TRUE TRUE FALSE FALSE FALSE
## $ react: num 597 1146 497 938 1080 ...
The three types discussed so far all assume that the vectors we combine are of the same length. What happens when they are not? Let’s generate a vector with five entries. Because we have not particular data for this example, we can just fill it with a sequence from 1 though 5.
five <- 1:5
five
## [1] 1 2 3 4 5
In this case the : is a shorthand for seq(1, 5, 1), meaning a sequence is generated from 1 through 5 in steps of 1. With the seq function you can generate all kinds of sequences - feel free to check help(seq).
Combining this five-entry vector with our other variables results in an error:
data.frame(color, text, cong, react, five)
## Error in data.frame(color, text, cong, react, five): arguments imply differing number of rows: 6, 5
which shows you that data.frame`s need all their variables to be of the same length. This makes sense, when you think about what the data represents: usually each row of a data set is a person or trial, why would some trials have less variables than others? But, say the reaction timed out for the sixth trial, this does not result in a shorter vector, but simply in that instance being a missing value - :code:`NA in R verbiage. You can achieve this by:
five <- c(five, NA)
NA`s can be used in any type of vector - they do not change the type of vector, they simply represent the absence of information. This turns the vector into a vector with six entries, the last of which is :code:`NA. If you are adding a vector to a data.frame, you do not need to enter all vectors, by the way. You can add a vector to an already existing data.frame:
data.frame(dat, five)
## color text cong react five
## 1 green green TRUE 597 1
## 2 purple purple TRUE 1146 2
## 3 blue blue TRUE 497 3
## 4 purple green FALSE 938 4
## 5 red blue FALSE 1080 5
## 6 green red FALSE 1304 NA
One final word of caution: in R there is a special exception to the “must be of the same length”-rule. An exception is made when the shorter vector is a divisor of the longer vector. In that instance, the shorter vector is repeated until the data is filled. Let’s take the vector of 1 through 3 as an example:
three <- 1:3
data.frame(color, text, cong, react, three)
## color text cong react three
## 1 green green TRUE 597 1
## 2 purple purple TRUE 1146 2
## 3 blue blue TRUE 497 3
## 4 purple green FALSE 938 1
## 5 red blue FALSE 1080 2
## 6 green red FALSE 1304 3
so you will need be careful when adding new variables: always check whether the new data is actually what you intended.
The final way of storing data is simultaneously the least efficient and most regularly used form: lists. The latter is the case because most functions return lists as results. For very large data sets I would advise against using list, because they tend to slow everything down quite drastically. In general, if it is at all possible to simplify your data into a data type that is above it in the table I presented at the beginning of this section, you should probably do it.
Nevertheless, lists are useful, because you can combine all types of information and data. A simple case is a list of different vectors:
lst <- list(color, text, cong, react)
str(lst)
## List of 4
## $ : chr [1:6] "green" "purple" "blue" "purple" ...
## $ : chr [1:6] "green" "purple" "blue" "green" ...
## $ : logi [1:6] TRUE TRUE TRUE FALSE FALSE FALSE
## $ : num [1:6] 597 1146 497 938 1080 ...
The structure of this looks eerily similar to that of the data.frame we looked at before. That is because, as mentioned, :code:`data.frame`s are simply special lists. The difference is that you can store anything in your list, even other lists!
meta_list <- list('Person 1', lst, dat)
str(meta_list)
## List of 3
## $ : chr "Person 1"
## $ :List of 4
## ..$ : chr [1:6] "green" "purple" "blue" "purple" ...
## ..$ : chr [1:6] "green" "purple" "blue" "green" ...
## ..$ : logi [1:6] TRUE TRUE TRUE FALSE FALSE FALSE
## ..$ : num [1:6] 597 1146 497 938 1080 ...
## $ :'data.frame': 6 obs. of 4 variables:
## ..$ color: Factor w/ 4 levels "blue","green",..: 2 3 1 3 4 2
## ..$ text : Factor w/ 4 levels "blue","green",..: 2 3 1 2 1 4
## ..$ cong : logi [1:6] TRUE TRUE TRUE FALSE FALSE FALSE
## ..$ react: num [1:6] 597 1146 497 938 1080 ...
In many cases, the results of functions are rather complicated lists. For example, the result of a regression in R is a list of 13 elements of various types and sizes, so it is useful to know how to interact with lists, even if your own data should ideally be stored in a different format.
Extracting data¶
In the previous two sections the focus was on combining data into larger objects. While this is normally what you do when gathering data, inspecting specific information is just as important, especially because, as noted above, results that are output by analysis functions are often lists.
Let us start with the simplest case: extracting an element from a vector. The four vectors we generated in the section Vectors all contain six elements. Take a closer look at the structure of the reaction times:
str(react)
## num [1:6] 597 1146 497 938 1080 ...
The [1:6] tells you that this vector contains elements one through six. The brackets indicate how to subset these elements. For example, if you want to see the fourth element of this vector:
react[4]
## [1] 938
This returns the fourth element. In R the brackets [ ] are the most basic way of selecting specific elements in any object. What you write in those brackets then determines what you select. You can also explicitly deselect something that is not of interest to you:
react[-4]
## [1] 597 1146 497 1080 1304
The important thing to keep in mind here, is that this selection works, like most things in R, for vectors just as well as it does for single elements. So creating a selection vector can help:
sel <- c(1, 3, 5)
react[sel]
## [1] 597 497 1080
of course, you do not need to create an object for the selection vector, you can pass it directly (i.e. react[c(1, 3, 5)]) and it will have the same effect. This works according to the same principle we discussed in Functions and arguments: functions can be nested in functions and, because they are evaluated from the inside out, their results will be used as the argument. In this case the c function is evaluated and its result (the vector) is passed to the brackets. In case you were wondering: you can also use this to select the same element multiple times.
react[c(1, 1, 2)]
## [1] 597 597 1146
The selection we performed up until here was based on the numeric representation of an element’s position in a vector. You can also use character and logical vectors to select elements. We will see how this works for character vectors in a second, but the logical vector provides an immense amount of flexibility. Recall the vector we constructed to indicate, whether text and color are the same (i.e. whether it is a congruent condition). We can now use this vector to logically select the elements of any other vector that is also six elements long. So, to select the reaction times for congruent conditions:
react[cong]
## [1] 597 1146 497
For the incongruent conditions, we can simply use the ! to negate the logical vector:
react[!cong]
## [1] 938 1080 1304
Because vectors are one-dimensional, selecting elements from them requires only one information. Most data are stored in two (or more) dimensional objects, however. As shown in Combining data, there are four standard variants of data storage. First, let’s look at the matrix of colors and texts:
mat <- cbind(color, text)
mat
## color text
## [1,] "green" "green"
## [2,] "purple" "purple"
## [3,] "blue" "blue"
## [4,] "purple" "green"
## [5,] "red" "blue"
## [6,] "green" "red"
This matrix has six rows and two columns, so to select any single element we need to locate it along these two dimensions. So to select the “red” text, we need to navigate to the 6th row and the 2nd column:
mat[6, 2]
## text
## "red"
In R, as is usual, the first dimension of matrices is the row and the second dimension is the columns. Thus, the brackets we use as our “selection function”, now take two arguments. If we want all elements along one dimension we can use:
mat[1, ] # All elements of the 1st row
## color text
## "green" "green"
mat[, 1] # All elements of the 1st column
## [1] "green" "purple" "blue" "purple" "red" "green"
It is possible to select elements in matrices by using a one-dimensional notation: mat[7] will return the seventh overall element, first counting through all rows of the first column, then continuing with second column and so on. However, I would strongly advise you to use the two-dimensional version of selecting data from matrices for now.
The two-dimensional selection procedure is, of course, extendable to arrays of more than two dimensions, where you simply provide more arguments to the brackets (e.g. [3, 1, 4] will select the 4th row, 1st column, 4th layer). If you want to select more than one element, you would need to provide vectors determining your selection along on dimension. So, let’s say you want the 1st and 4th element of the 1st column:
mat[c(1, 4), 1]
## [1] "green" "purple"
Again, this selection procedure is not limited to numeric vectors, but can also be performed using logical or character vectors. As an example for the use of logical vectors, we can select all rows of the matrix, which are congruent conditions:
mat[cong, ]
## color text
## [1,] "green" "green"
## [2,] "purple" "purple"
## [3,] "blue" "blue"
Character vectors can be used for selection, if the dimensions of a matrix have names. Let’s check:
dimnames(mat)
## [[1]]
## NULL
##
## [[2]]
## [1] "color" "text"
This is actually the first time we see a function returning a list! The information we can glean from it is that the first dimension (the rows) has NULL names - so no names here. The second dimension (the columns) contains the names color and text. These names were simply inherited from the names of the objects we used cbind on.
So, knowing the names, we can use a character vector to select columns from this matrix:
mat[, 'color']
## [1] "green" "purple" "blue" "purple" "red" "green"
As we discussed in Combining data, matrices only work in a limited number of situations and data.frame`s are much more widespread. Then why did we just spend so much time on matrices? Well, because a :code:`data.frame is just as two-dimensional as a matrix, so the same procedures we discussed for matrices also work for them.
dat[1, 4] # 1st row, 4th column
## [1] 597
dat[, 3] # All of the 3rd column
## [1] TRUE TRUE TRUE FALSE FALSE FALSE
dat[c(2, 3), 3] # Elements 2 and 3 of the 3rd column
## [1] TRUE TRUE
dat[cong, ] # Only rows for which cong == TRUE
## color text cong react
## 1 green green TRUE 597
## 2 purple purple TRUE 1146
## 3 blue blue TRUE 497
Remember, that this can be combined with the creation of objects discussed. So, if you want to perform some analyses separately for congruent and incongruent stimuli, you can just create two new :code:`data.frame`s, which contain only parts of the originals:
con <- dat[cong, ]
inc <- dat[!cong, ]
This has the potential to make it much easier to handle subsets of data, when you perform a lot of analyses on certain parts, but not others.
Next to the procedures for matrices, the procedures for lists also work on data.frame`s, because they are very specific types of lists. The most prominent way of selection from :code:`data.frame`s is by using the :code:`$:
dat$react
## [1] 597 1146 497 938 1080 1304
This type of selection can be read as “in dat, select variable react”. This is used in extremely many R scripts, because this allows us to store combined data and then quickly pick a single variable for which we want to calculate some statistics. This procedure also works for lists and can even be extended to cases where multiple $ are used in sequence. Say you have multiple data frames in a list. In that situation you can select a variable in a data frame in a list by list_name$data_name$variable_name. However, keep in mind, that for the $ approach to work, all elements you are trying to select must be named! For data.frame`s, R generates names automatically (:code:`V1, V2, and so on, if you do not provide names), but this is not the case for regular lists.
To see the names of the variables in your data set, you can simply use:
names(dat)
## [1] "color" "text" "cong" "react"
If you are more comfortable with using functions instead of the brackets or the $, you can also use the subset function, which allows you to achieve the same results. If you are interested in seeing how that function works, I encourage you to take a look at help(subset).
Adding new data¶
We have now seen how to combine separate objects to one data set and how to select and extract specific information from those data sets. The last step is to add new information to already existing data.
As we have seen above, we can use cbind or rbind to combine multiple vectors either by column or by row. This also works for adding columns and rows to pre-existing matrices. Additionally, we already saw that the data.frame function can be used either to combine vectors into multiple columns of a :cdoe:`data.frame` or to add vectors to existing ones.
You can also use the approaches for identifying single rows and columns to add new data. Perhaps the most common scenario is adding new variables to a data set. Say we want to use the deviation of a reaction time from a person’s normal reaction time in our analyses, instead of the raw time we measured. This could have the advantage of controlling for person-specific variables that influence the overall reaction time, but not deviations in our experiment. As such a baseline we can use the arithmetic mean of the reaction times as a placeholder for a person’s average reaction time:
mean(dat$react)
## [1] 927
So, to compute the deviation from the mean on each reaction time:
dat$react - mean(dat$react)
## [1] -330 219 -430 11 153 377
This is again a vector of 6. We could create an object by using the <-, but that would not add the variable to the data.frame. It would simply become a free floating object in our environment. To keep data organized, it is better to store them together in a single object.
There are now multiple ways to achieve the goal of adding a new variable to the data.frame, but the one you will probably encounter most often is by using the $ notation. Let’s say the new variable is supposed to be called dif, for difference. Let’s see whether this variable already exists in the data set:
dat$dif
## NULL
As you may have guessed, it doesn’t. This means, we can simply create it by assigning values to it.
dat$dif <- dat$react - mean(dat$react)
This works just like it does for creating objects in the environment. If we use a name that does not exist, the variable is created. If we use a name of a variable that exists within the data.frame, it is overwritten without warning.
This variable now exists only in the data set. It does not exist freely in the environment:
dif
## Error in eval(expr, envir, enclos): object 'dif' not found
This is especially useful, when you are handling many data sets simultaneously, because it can help you avoid overwriting information you may have needed. Instead a variable is assigned straight to the data.frame it is related to.
Adding a new variable this way has the benefit of it being named in the process. You could also use the bracket notation to get this done. In our case the data.frame now consists of 5 columns:
ncol(dat)
## [1] 5
So, if we were to add a new variable it would be most logical to add it as the 6th, or generally speaking, the ncol(dat) + 1 column:
dat[, ncol(dat) + 1] <- dat$react - mean(dat$react)
dat
## color text cong react dif V6
## 1 green green TRUE 597 -330 -330
## 2 purple purple TRUE 1146 219 219
## 3 blue blue TRUE 497 -430 -430
## 4 purple green FALSE 938 11 11
## 5 red blue FALSE 1080 153 153
## 6 green red FALSE 1304 377 377
This adds the variable in the appropriate spot, but does not provide it with a name. Instead it gets the generic name V6. You could then name it manually, by assigning a name via the names function. Because the result of names is a vector, you can assign the name for this specific variable, by selecting the appropriate element:
names(dat)[ncol(dat)] <- 'dif2'
names(dat)
## [1] "color" "text" "cong" "react" "dif" "dif2"
Because this variable is the same as the variable we added previously, it makes no sense to keep both of them. To remove a variable from a data.frame, it needs to be overwritten with nothing. As you may have noticed, R represents nothing with NULL:
dat$dif2 <- NULL
dat
## color text cong react dif
## 1 green green TRUE 597 -330
## 2 purple purple TRUE 1146 219
## 3 blue blue TRUE 497 -430
## 4 purple green FALSE 938 11
## 5 red blue FALSE 1080 153
## 6 green red FALSE 1304 377
Using the bracket approach, we can also add new rows to our data.frame. The only thing we need to keep in mind here, is that the vectors must be constructed correctly, for the data.frame to accept them. First, let’s remove the new dif variable, so we can return to our original data.frame:
dat$dif <- NULL
str(dat)
## 'data.frame': 6 obs. of 4 variables:
## $ color: Factor w/ 4 levels "blue","green",..: 2 3 1 3 4 2
## $ text : Factor w/ 4 levels "blue","green",..: 2 3 1 2 1 4
## $ cong : logi TRUE TRUE TRUE FALSE FALSE FALSE
## $ react: num 597 1146 497 938 1080 ...
this data.frame now consists of our four original variables. To add a new row, much like we added a new column, we can simply assign values to the nrow(dat) + 1 row:
dat[nrow(dat) + 1, ] <- c('red', 'red', TRUE, 627)
dat
## color text cong react
## 1 green green TRUE 597
## 2 purple purple TRUE 1146
## 3 blue blue TRUE 497
## 4 purple green FALSE 938
## 5 red blue FALSE 1080
## 6 green red FALSE 1304
## 7 red red TRUE 627
Be aware that we are only allowed to add rows that fulfill all the requirements of our data.frame: they must be of the correct length (i.e. the number of columns of the data.frame) and the values in each spot must be compatible with the variables. Factors generally prove most problematic in such situations:
dat[nrow(dat) + 1, ] <- c('orange', 'purple', FALSE, 844)
## Warning in `[<-.factor`(`*tmp*`, iseq, value = "orange"): invalid factor
## level, NA generated
dat
## color text cong react
## 1 green green TRUE 597
## 2 purple purple TRUE 1146
## 3 blue blue TRUE 497
## 4 purple green FALSE 938
## 5 red blue FALSE 1080
## 6 green red FALSE 1304
## 7 red red TRUE 627
## 8 <NA> purple FALSE 844
Factors in data.frame`s only accept values with are contained in their levels. If we want to add the last row we first need to add :code:’orange’` as a level of color:
levels(dat$color) <- c(levels(dat$color), 'orange')
levels(dat$color)
## [1] "blue" "green" "purple" "red" "orange"
dat[nrow(dat), ] <- c('orange', 'purple', FALSE, 844)
dat
## color text cong react
## 1 green green TRUE 597
## 2 purple purple TRUE 1146
## 3 blue blue TRUE 497
## 4 purple green FALSE 938
## 5 red blue FALSE 1080
## 6 green red FALSE 1304
## 7 red red TRUE 627
## 8 orange purple FALSE 844
4.1.5. Getting data into and out of R¶
Up until this point, everything we have discussed was handled by R internally. If you followed along with all the examples your workspace should look something like this:
ls()
## [1] "color" "color_fac" "color_fac2" "color_num" "color_ord"
## [6] "con" "cong" "dat" "dat2" "five"
## [11] "inc" "lst" "mat" "meta_list" "react"
## [16] "sel" "text" "three"
Most of it is junk that we don’t need, but we may want to keep the data frame containing the results of the Stroop trials.
In all functions which relate to loading, importing, saving, and exporting data, R requires filepaths to be specified. This means that you would need to determine the entire path in an absolute sense, every time you interact with a file. This can get quite annoying, so there is a specific way, R handles relative paths, which is called the working directory. (For those of you familiar with the terminal in Mac OS X and Linux or the command line in Windows, this is the same way directories are handled in those.) This is simply the directory you are currently working in - if you want to save or load any file in this specific directory, you can simply provide the filename. To see what your current working directory is, you can use
getwd()
## [1] "/home/martin/smobsc/docs/chapter_ana"
Of course, your current working directory will have a different name. Generally, I would recommend setting up a folder for each project you are working on and then using that folder as your working directory. This saves you the time of typing in absolute paths and prevents you from accidentally storing files somewhere, where you need to look for them or accidentally overwrite something (again, R will not warn you, if a file already exists). You can set your working directory by using
setwd('PATH/TO/YOUR/DIRECTORY')
In the easiest case you can simply navigate to your folder using your file system and copy its location (listed in its properties). Windows users should be aware: Windows uses backslashes \` to denote subfolders, while R uses forwardslashes :code:/. So, if you copy the folder location on a Windows machine you will need to replace all the :code:` with / in your filepaths.
If you want to see which files are in your working directory, you can use
dir()
to check. In most cases I highly recommend having an additional subfolder called “data” in the folder for your project. Then, you can use ./data/ to save and load from there.
Saving and loading¶
R uses two own data formats - RDA and RDS - which you can use to save data to and load data from. Here’s a quick overview:
| Data format | RDA | RDS |
|---|---|---|
| File extension | .rda, .RData | .rds |
| Save function | save |
saveRDS |
| Load function | load |
readRDS |
| Objects saved | Multiple | Single |
| Loading behavior | Restore objects in environment | Assign loaded data to new object |
Generally speaking, RDA is best suited when you are storing multiple objects simultaneously and you do not need them separately. RDS on the other hand is best suited for use with single objects. Most people use RDA regardless of whether they are storing multiple objects or single objects, but we will look at both, because using RDS can be extremely beneficial when using the same routines multiple times - for example if you have a single data frame for each test subject.
First, let’s look at how saving and loading RDAs works. For this example, we will save only the data frame dat in our “data” subfolder:
save(dat, file = './data/dat.rda')
Now that we have saved what is relevant to us, let’s clear the entire environment, so we can be sure that loading actually loads a file and we are not just seeing the object we already had in our environment:
rm(list = ls())
ls()
## character(0)
Our environment is empty now. So, as stated above, loading the RDA should restore the object dat in our environment:
load('./data/dat.rda')
ls()
## [1] "dat"
So that is all it takes to save and load in R. Let’s take a quick look at the alternative: RDS.
saveRDS(dat, './data/dat.rds')
rm(list = ls())
Loading an RDS requires you to assign the result to an object. This has the benefit that it allows you to use object names that are specific to the script you are working with to analyze your data, not to the one creating it.
stroop <- readRDS('./data/dat.rds')
stroop
## color text cong react
## 1 green green TRUE 597
## 2 purple purple TRUE 1146
## 3 blue blue TRUE 497
## 4 purple green FALSE 938
## 5 red blue FALSE 1080
## 6 green red FALSE 1304
## 7 red red TRUE 627
## 8 orange purple FALSE 844
In general, I would recommend using RDS whenever possible. You might be wondering: if RDA can save multiple objects at once, why not save the entire environment? This is actually what RStudio asks you to do, when you close it. Don’t. The core idea of using a programming language like R is that you can use the script to recreate everything that was done. Relying on objects in your workspace that you cannot recreate using your script means that your data preparation and analyses cannot be reconstructed by anyone else.
Importing and exporting¶
Most of the programs used to assess data do not produce RDA or RDS data. Most often what this means is that you will have to import and clean data, then save it as RDA or RDS, and use those files for your analysis scripts. For a quick glance of how to import from the data-formats provided by SPSS, SAS, STATA, and so on, you can take a look at the overview provided on the `Quick-R website<https://www.statmethods.net/input/importingdata.html>`_. In this section we will take a more in-depth look at importing from text-formats, because they are also often what we get from Python-based assessments.
The text-formats you will see most often are .csv, .txt, and .dat. While there is a specific function for .csv files (take a look at help(read.csv) if you are interested), the general function read.table can be used for all three types, so it is the best one to discuss here.
The experiment that was discussed in the previous sections results in multiple .csv files - one for each participant. We will take a look at how to efficiently extract all of them in just a few lines of code in the next chapter, here we will concentrate on importing one of them.
The read.table command is the first one we are looking at, that requires quite a few arguments to get it to do what we want. Let’s take a look at all the arguments (you could also use help(read.table)):
args(read.table)
## function (file, header = FALSE, sep = "", quote = "\"'", dec = ".",
## numerals = c("allow.loss", "warn.loss", "no.loss"), row.names,
## col.names, as.is = !stringsAsFactors, na.strings = "NA",
## colClasses = NA, nrows = -1, skip = 0, check.names = TRUE,
## fill = !blank.lines.skip, strip.white = FALSE, blank.lines.skip = TRUE,
## comment.char = "#", allowEscapes = FALSE, flush = FALSE,
## stringsAsFactors = default.stringsAsFactors(), fileEncoding = "",
## encoding = "unknown", text, skipNul = FALSE)
## NULL
To know which settings to use, we need to know what our data files look like. Take a look at the first file, the contents should look something like this:
## text,is_lure,key,yes_key,rt,subject
## Bier,neutral,l,a,2.1808581352200003,0
## Dinosaurier,neutral,l,a,0.9811301231380001,0
## Volkswagen,correct,a,a,1.0397160053299999,0
## Sibirien,neutral,l,a,2.89859485626,0
We can see that the first line in our data file contains the variable names, meaning we have to set header = TRUE in our read.table. Additionally, the variables are separated by commas, meaning we should use sep = ','. Let’s see where this leaves us:
drm0 <- read.table('./data/0_recognized.csv',
header = TRUE, sep = ',')
str(drm0)
## 'data.frame': 27 obs. of 6 variables:
## $ text : Factor w/ 27 levels "Achtung","Auto",..: 4 7 25 24 12 5 19 16 10 8 ...
## $ is_lure: Factor w/ 3 levels "correct","lure",..: 3 3 1 3 1 1 3 1 3 3 ...
## $ key : Factor w/ 2 levels "a","l": 2 2 1 2 1 1 2 1 2 2 ...
## $ yes_key: Factor w/ 1 level "a": 1 1 1 1 1 1 1 1 1 1 ...
## $ rt : num 2.181 0.981 1.04 2.899 2.87 ...
## $ subject: int 0 0 0 0 0 0 0 0 0 0 ...
This seems to have done what we wanted. Remember, there is no problem with simply trying things, running your code, to see what happens. As I stated above, it is one of the main benefits of using R: you do not have to compile your code.
We looked at how you can save this file in an RDA or RDS format in the last section. You can also export it to text-formats to be able to use it in other software. To export, you can use write.table, which works very similar to read.table:
args(write.table)
## function (x, file = "", append = FALSE, quote = TRUE, sep = " ",
## eol = "\n", na = "NA", dec = ".", row.names = TRUE, col.names = TRUE,
## qmethod = c("escape", "double"), fileEncoding = "")
## NULL
The first argument that is required is the object we want to export. In our case, this is drm0. The second is, of course, the file we want to store it in. As you can read in the help-file for this function, append indicates whether you want to add what you are exporting to the bottom of an already existing file. If this is set to FALSE, files that already exist will simply be overwritten. To reproduce the file we imported, we would need to set:
write.table(drm0, './data/export.csv',
quote = FALSE, sep = ',',
row.names = FALSE)
This results in a file that looks like this:
## text,is_lure,key,yes_key,rt,subject
## Bier,neutral,l,a,2.18085813522,0
## Dinosaurier,neutral,l,a,0.981130123138,0
## Volkswagen,correct,a,a,1.03971600533,0
## Sibirien,neutral,l,a,2.89859485626,0
4.1.6. Closing words¶
In this chapter we took a “quick” glance at the basics of R. Starting to get along with R can feel pretty overwhelming at first, but always remember that there is no penalty for trying something and getting it wrong a couple of times. When seeing warnings and errors, don’t panic. Just remember to use help frequently.
If you followed along with all the examples in this chapter you should have a general idea of how to use R as a calculator (Commenting and basic functionality) and understand the basic rules of how to use functions (Functions and arguments). You should also know what objects are and how to create them (Objects and the Environment). What we will need in the upcoming sections are basic skills in Handling data, so we can prepare our analyses.
In the next chapter, we will dive into some more in-depth concepts of R, but if you want some other sources to broaden your knowledge, I would recommend starting with Hadley Wickhams `Advanced R<http://adv-r.had.co.nz/>`_. If your looking for answers to specific questions, check out `R on stackoverflow<https://stackoverflow.com/questions/tagged/r>`_.